Data wrangling : 6 étapes pour transformer vos données brutes en actifs stratégiques

Le data wrangling, aussi appelé « munging », consiste à dompter des flux de données disparates pour les rendre exploitables. Dans un environnement où les entreprises collectent des volumes massifs d’informations, la donnée brute ressemble souvent à un gisement inexploitable sans un raffinage méticuleux. Sans cette étape, les algorithmes de machine learning et les tableaux de bord les plus sophistiqués produisent des résultats erronés ou biaisés. Ce processus, qui occupe jusqu’à 80 % du temps d’un data scientist, est le fondement de toute stratégie data-driven réussie.
Qu’est-ce que le data wrangling et pourquoi est-il indispensable ?
Le terme « wrangling » emprunte son imagerie au monde du bétail : il s’agit de rassembler, de trier et de diriger des éléments indisciplinés vers un enclos structuré. En informatique, le data wrangling désigne l’ensemble des opérations permettant de convertir et de cartographier des données d’un format brut vers un format prêt pour l’analyse. Ce n’est pas une simple tâche technique, mais une transformation de la valeur.
Une nuance fondamentale avec le data cleaning
On confond souvent le data wrangling avec le data cleaning. Si le nettoyage est une composante du wrangling, il n’en constitue qu’une partie. Le nettoyage se concentre sur la suppression des erreurs et des doublons, tandis que le wrangling englobe une vision plus large : la fusion de sources multiples, le changement de structure des fichiers et l’enrichissement contextuel. Le nettoyage répare la donnée, le wrangling la prépare pour son usage métier.
L’impact économique de la préparation des données
Le marché mondial du data wrangling devrait atteindre 7,6 milliards de dollars d’ici 2031. Cette croissance s’explique par une réalité simple : une mauvaise préparation des données coûte cher. Qu’il s’agisse d’une erreur de segmentation marketing due à des adresses mal formatées ou d’un diagnostic médical faussé par des unités de mesure incohérentes, les conséquences financières sont directes. Investir dans un pipeline de wrangling robuste sécurise vos investissements en Business Intelligence et en intelligence artificielle.
Le processus itératif : les 6 étapes clés du data wrangling
Le data wrangling suit un cycle itératif. Chaque étape permet d’affiner la compréhension du jeu de données et d’ajuster les transformations nécessaires.
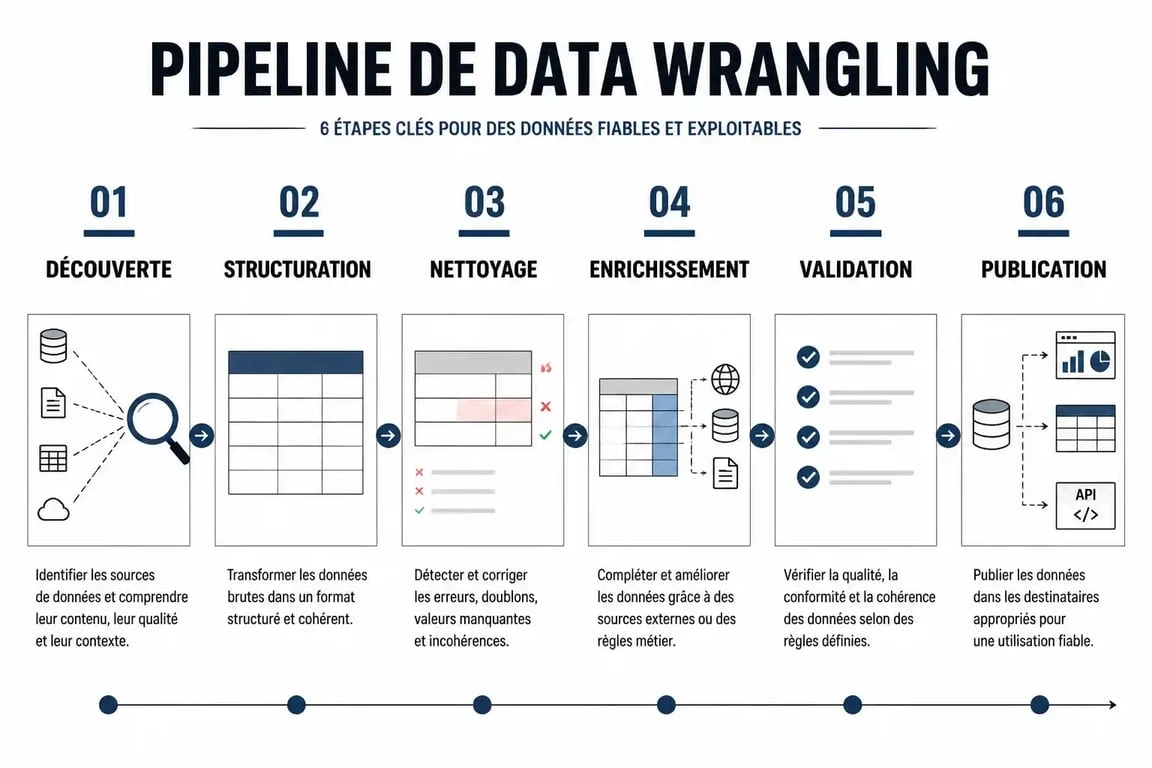
- La découverte (Discovery) : Avant toute manipulation, analysez le contenu des fichiers. Identifiez les types de variables, les tendances et les anomalies flagrantes.
- La structuration (Structuring) : Les données brutes arrivent souvent sans forme précise, comme des logs serveurs ou des fichiers JSON complexes. Organisez l’information pour qu’elle s’intègre dans le schéma de destination, en séparant des colonnes ou en pivotant des tableaux.
- Le nettoyage (Cleaning) : Traitez les valeurs manquantes, supprimez les doublons et corrigez les fautes de frappe ou les formats de date hétérogènes.
- L’enrichissement (Enriching) : Ajoutez de la valeur en croisant les données existantes avec des sources externes, comme des données météo ou de géolocalisation, pour donner plus de relief à l’analyse.
- La validation (Validating) : Vérifiez la cohérence logique des données. Par exemple, assurez-vous qu’une date de naissance n’est pas postérieure à une date de commande.
- La publication (Publishing) : Une fois les données propres et structurées, chargez-les dans l’entrepôt de données (Data Warehouse) ou transmettez-les aux outils de visualisation.
Maîtriser le flux : naviguer dans la vague des données
Face à l’accélération des flux numériques, les entreprises gèrent une vague d’informations en continu. Cette dynamique change la nature du travail de préparation. On ne prépare plus un fichier Excel une fois par mois, on conçoit des systèmes capables d’absorber ce mouvement perpétuel. Cette approche demande d’anticiper la dérive des données, où la nature des informations collectées change subtilement au fil du temps. En percevant la donnée comme un flux organique, le data wrangler devient un architecte de la résilience, capable d’ajuster ses filtres sans interrompre le processus décisionnel.
Outils et technologies : du code au libre-service
Le choix des outils dépend de la complexité des données et des compétences de l’équipe. On distingue deux familles de solutions.
Le wrangling par le code (Python et R)
Pour les data scientists, les bibliothèques comme Pandas (Python) ou Tidyverse (R) sont les références. Elles offrent une flexibilité totale pour manipuler des millions de lignes, effectuer des calculs complexes et automatiser des pipelines de transformation. L’avantage réside dans la reproductibilité : un script est réutilisé indéfiniment sur de nouveaux jeux de données.
Les plateformes de Data Wrangling en libre-service
Pour démocratiser l’accès à la donnée, des outils de « Self-Service Data Prep » ont vu le jour. Des solutions comme Alteryx, Talend ou Power Query permettent à des profils moins techniques, comme les analystes métier, de transformer des données via des interfaces visuelles. Voici un aperçu des principaux acteurs du marché :
| Outil | Cible principale | Points forts |
|---|---|---|
| Pandas (Python) | Data Scientists | Flexibilité totale, gratuité, intégration ML |
| Alteryx | Analystes Business | Interface visuelle, puissance de calcul, automatisation |
| Trifacta | Data Engineers | Intelligence artificielle suggérant des transformations |
| Tableau Prep | Utilisateurs BI | Intégration parfaite avec l’écosystème Tableau |
Les bénéfices concrets pour les différents métiers
Le data wrangling est un levier de performance pour chaque département de l’entreprise.
Marketing et expérience client
En fusionnant les données provenant des réseaux sociaux, du CRM et du support client, le marketing obtient une vue à 360 degrés de l’utilisateur. Le wrangling réconcilie des identifiants différents, comme un email ou un numéro de téléphone, pour créer un profil unique et cohérent, évitant ainsi d’envoyer des promotions non pertinentes.
Finance et gestion des risques
Dans le secteur bancaire, la détection de la fraude repose sur l’analyse de signaux faibles perdus dans des téraoctets de transactions. Un wrangling efficace normalise les flux provenant de différents pays et devises en temps réel, rendant les modèles de détection beaucoup plus réactifs.
Ressources Humaines
Les RH utilisent ces techniques pour analyser le turnover ou l’engagement. En croisant les données de paie avec les enquêtes de satisfaction, le département identifie des corrélations invisibles, à condition que les données sources aient été correctement nettoyées et mappées au préalable.
Conclusion : vers une culture de la donnée propre
Le data wrangling est le héros de l’ombre de la révolution numérique. Moins médiatisé que l’intelligence artificielle, il en est le carburant indispensable. Pour les organisations, l’enjeu est de passer d’un wrangling artisanal à un processus industrialisé et collaboratif. En dotant les collaborateurs des bons outils et en instaurant une rigueur dès la collecte, les entreprises se donnent les moyens de transformer leurs données en décisions stratégiques.
- La méthode de l’arbre des causes : analyser les faits pour prévenir durablement les accidents - 25 juillet 2026
- Google Analytics : guide pratique pour configurer vos rapports et piloter vos performances - 25 juillet 2026
- Formation SEO : quel budget prévoir et comment financer votre montée en compétences ? - 24 juillet 2026
Articles qui pourraient vous intéresser :
 Ordinateur portable pour travailler : 16 Go de RAM et 3 autres critères pour éviter les ralentissements
Ordinateur portable pour travailler : 16 Go de RAM et 3 autres critères pour éviter les ralentissements
 Tableau CRM : 5 indicateurs pour transformer vos données en revenus
Tableau CRM : 5 indicateurs pour transformer vos données en revenus
 CRM sur mesure vs standard : quand la personnalisation devient un levier de rentabilité
CRM sur mesure vs standard : quand la personnalisation devient un levier de rentabilité
 Webmastering : 4 leviers techniques pour sécuriser et pérenniser votre site
Webmastering : 4 leviers techniques pour sécuriser et pérenniser votre site